阅读材料 5 - 规格说明 | MIT 6.005 学习笔记
MIT 6.005 Spring 2016 的 OCW 版本的学习笔记。此篇笔记涉及的内容为 Reading 5 Specifications。
课程目标
- 了解方法规格说明中的前置条件和后置条件,并能编写正确的规格说明
- 能够根据规格说明编写测试
- 知道 Java 中受检查异常和无检查异常的区别
- 了解如何使用异常处理特殊结果
简介
规格说明是团队合作的关键。如果没有规格说明,就不可能将实现方法的工作委派出去。规格说明就像一份合同:实现者有责任履行合同,而方法的使用者可以依赖这份合同。事实上,我们会发现,就像真正的法律合同一样,规格说明对双方都提出了要求:当规格说明有前置条件时,使用者也必须遵守。
在本篇阅读材料中,我们将探讨方法规格说明所扮演的角色。我们将讨论什么是前置条件和后置条件,它们对方法的实现者和使用者分别意味着什么。我们还将讨论如何使用异常,它是 Java、Python 和许多其他现代语言中的一个重要语言特性,让我们能够使方法的接口更安全,更容易理解。
第一部分:规格说明
在我们深入规格说明的结构和含义之前...
为什么要有规格说明
程序中许多最糟糕的错误都源于对两段代码之间接口行为的误解。尽管每个程序员心中都有自己的规格说明,但并非所有程序员都会将其写下来。因此,团队中的不同程序员心中有不同的规格说明。当程序出错时,很难确定错误出在哪里。代码中的精确规格说明可以让您分配责任(给代码片段,而不是人!),并可以避免您苦苦思考修复应该放在何处。
规格说明对方法的使用者很有用,因为它们可以让您不必再阅读代码。如果您不相信阅读规格说明比阅读代码更容易,那么请看看一些标准的 Java 规格说明,并将它们与实现这些规格说明的源代码进行比较。
下面是一个来自 BigInteger 中的一个方法的例子:
| add |
|---|
public BigInteger add(BigInteger val)返回一个值为 (this + val) 的 BigInteger参数: val - 要加到此 BigInteger 上的值返回: this + val |
if (val.signum == 0)
return this;
if (signum == 0)
return val;
if (val.signum == signum)
return new BigInteger(add(mag, val.mag), signum);
int cmp = compareMagnitude(val);
if (cmp == 0)
return ZERO;
int[] resultMag = (cmp > 0 ? subtract(mag, val.mag)
: subtract(val.mag, mag));
resultMag = trustedStripLeadingZeroInts(resultMag);
return new BigInteger(resultMag, cmp == signum ? 1 : -1);BigInteger.add 的规格说明对于用户来说简单明了,而且如果我们对边界情况有疑问,BigInteger 类还提供了额外的人类可读文档。如果只有代码,我们就必须从 BigInteger 构造函数、compareMagnitude、subtract 和 trustedStripLeadingZeroInts 开始阅读。
规格说明对方法的实现者有好处,因为规格说明让实现者可以在不告诉用户的情况下自由改变实现。规格说明还可以使代码更快。我们将看到,使用较弱的规格说明可以排除方法可能被调用的某些状态。这种对输入的限制可能会让实现者跳过不再需要的昂贵检查,而使用更高效的实现。
合同就像使用者和实现者之间的 防火墙。它使使用者免受单元工作细节的影响 —— 如果您有程序的规格说明,您就不需要阅读程序的源代码。它也使实现者免于了解单元的使用细节;实现者不必询问每个用户打算如何使用该单元。这道防火墙实现了 解耦 (decoupling),允许独立更改单元代码和客户端代码,只要更改符合规格说明 —— 各自遵守自己的义务。
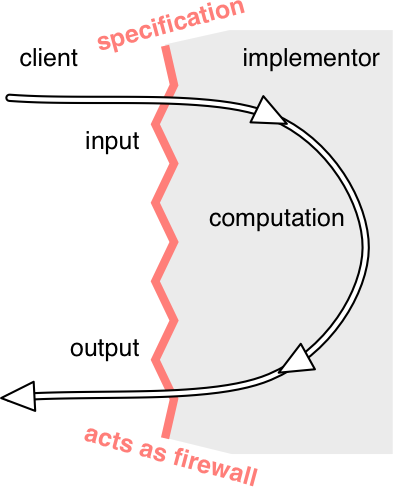
行为等效性
考虑下面的两个方法。它们一不一样?
static int findFirst(int[] arr, int val) {
for (int i = 0; i < arr.length; i++) {
if (arr[i] == val) return i;
}
return arr.length;
}
static int findLast(int[] arr, int val) {
for (int i = arr.length -1 ; i >= 0; i--) {
if (arr[i] == val) return i;
}
return -1;
}当然,代码是不同的,所以从这个意义上说,它们是不同的;为了便于讨论,我们给它们起了不同的名字。为了确定行为等价性,我们的问题是能否用一种实现来替代另一种实现。
这些方法不仅有不同的代码,实际上还有不同的行为:
- 当
val不存在时,findFirst返回arr的长度,findLast返回-1; - 当
val出现两次时,findFirst返回较低的索引,findLast返回较高的索引。
但是,当 val 恰好出现在数组的一个索引处时,这两种方法的行为是相同的:它们都返回该索引。用户可能从不依赖其他情况下的行为。 每当他们调用该方法时,都会传入一个包含一个元素 val 的数组。 对于此类用户,这两种方法是相同的,我们可以从一种实现切换到另一种实现,而不会出现问题。
等价的概念存在于观察者 —— 即用户 —— 的眼中。为了能够用一种实现替代另一种实现,并知道何时可以接受这种替代,我们需要一种规格说明,准确告诉用户需要依赖什么。
在这种情况下,我们的规格说明可能是:
static int find(int[] arr, int val)
_requires_: val occurs exactly once in arr
_effects_: returns index i such that arr[i] = val规格说明的结构
一个方法的规格说明由几个子句组成:
- 一个 前置条件,使用关键字 requires 指定
- 一个 后置条件,使用关键字 effects 指定
前置条件是用户(即方法的调用者)的义务,是方法调用状态的条件。
后置条件是方法实现者的义务。如果前置条件对调用状态成立,方法就有义务遵守后置条件,如返回适当的值、抛出指定的异常、修改或不修改对象等。
整体结构是一种逻辑暗示:如果 在调用方法时前置条件成立,那么 在方法完成时后条件必须成立。
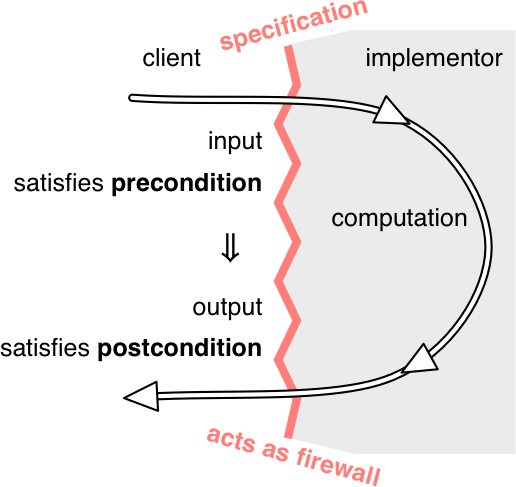
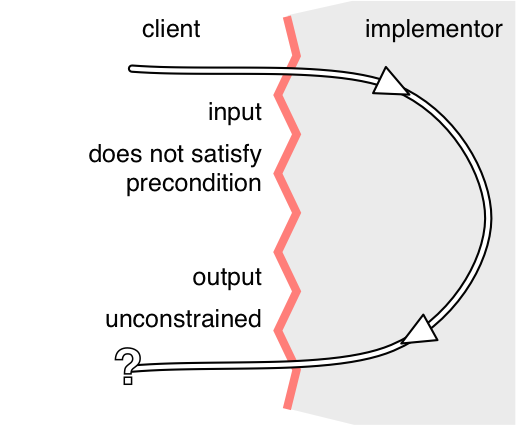
如果在调用方法时前置条件不成立,那么实现不受后置条件的约束。它可以自由地做任何事情,包括不终止、抛出异常、返回任意结果、进行任意修改等。
Java 中的规格说明
有些语言(例如 Eiffel)将前置条件和后置条件作为语言的基本组成部分,作为运行时系统(甚至编译器)可以自动检查的表达式,以强制执行用户和实现者之间的合同。
Java 并没有走得这么远,但它的静态类型声明实际上是方法的前置条件和后置条件的一部分,这部分内容由编译器自动检查和执行。 合同的其余部分 —— 我们不能写成类型的部分 —— 必须在方法前面的注释中描述,通常要靠人来检查和保证。
Java 有一个文档注释惯例,其中参数由 @param 子句描述,结果由 @return 和 @throws 子句描述。在可能的情况下,应将前置条件放在 @param 中,将后置条件放在 @return 和 @throws 中。 因此,形如这样的规格说明:
static int find(int[] arr, int val)
_requires_: val occurs exactly once in arr
_effects_: returns index i such that arr[i] = val在 Java 中可能是这样的:
/**
* Find a value in an array.
* @param arr array to search, requires that val occurs exactly once
* in arr
* @param val value to search for
* @return index i such that arr[i] = val
*/
static int find(int[] arr, int val)Java API 文档由 Java 标准库源代码中的 Javadoc 注释生成。 在 Javadoc 中记录规格说明可让 Eclipse 向您(以及您代码的客户端)显示有用的信息,并可让您以与 Java API 文档相同的格式生成 HTML 文档。
阅读:Javadoc Comments(《Javadoc 注释》)中的 Introduction , Commenting in Java , and Javadoc Comments
在撰写规格说明时,您也可以参考 Oracle 的 How to write Doc Comments(《如何编写文档注释》)。
空引用
在 Java 中,对象和数组的引用也可以使用特殊值 null,这意味着引用并不指向对象。空值是 Java 类型系统中一个不幸的漏洞。
原始数据类型不能是 null:
int size = null; // illegal
double depth = null; // illegal编译器的静态类型检查会发现这些错误。
另一方面,我们可以将 null 赋给任何非原始数据类型:
String name = null;
int[] points = null;编译器会在编译时接受这些代码。但在运行时却会出错,因为你不能调用任何方法,也不能使用这些引用中的任何字段:
name.length() // throws NullPointerException
points.length // throws NullPointerException请特别注意,null 与空字符串 "" 或空数组不同。 在空字符串或空数组上,你可以调用方法和访问字段。空数组或空字符串的长度为 0,而指向 null 的字符串变量的长度为零:调用 length() 会抛出 NullPointerException 异常。
还需注意的是,非原始数据类型的数组和 List 等集合可能是非空的,但包含 null 作为值:
String[] names = new String[] { null };
List<Double> sizes = new ArrayList<>();
sizes.add(null);一旦有人试图使用该集合的内容,这些空值很可能会导致错误。
空值既麻烦又不安全,因此建议您将其从您的设计词汇中删除。在这门课中,实际上在大多数优秀的 Java 编程中,都隐式地禁止在参数和返回值中使用空值。因此,每个方法都隐含了一个前置条件,即其对象和数组参数必须是非空值。每个返回对象或数组的方法都隐含有一个后置条件,即其返回值必须是非空的。如果一个方法允许参数为空值,则应明确说明这一点;如果该方法可能返回一个空值,则应明确说明这一点。但这些一般都不是好主意。所以,避免 null!
Java 有一些扩展,允许在类型声明中直接禁止 null,例如:
static boolean addAll(@NonNull List<T> list1, @NonNull List<T> list2)它可以在编译期或运行时自动检测 null。
谷歌对公司的核心 Java 库 Guava 中的 null 有自己的论述。 该项目解释说:
粗心大意地使用
null会导致各种各样的 bug。在研究 Google 代码库时,我们发现大约 95% 的集合中不应该有任何 null 值,而让这些集合快速失败而不是默默接受null会对开发人员有所帮助。此外,
null的模糊性也令人不快。例如,Map.get(key)返回的空值可能是因为 map 中的值为空,也可能是因为 map 中没有该值。 空可以表示失败,也可以表示成功,几乎可以表示任何意思。 使用 "空 "以外的其他含义会让你的意思更明确。
规格说明可能讨论的内容
方法的规格说明可以讨论方法的参数和返回值,但绝不应涉及方法的局部变量或方法类的私有字段。你应该考虑使具体实现对规格说明的读者不可见。
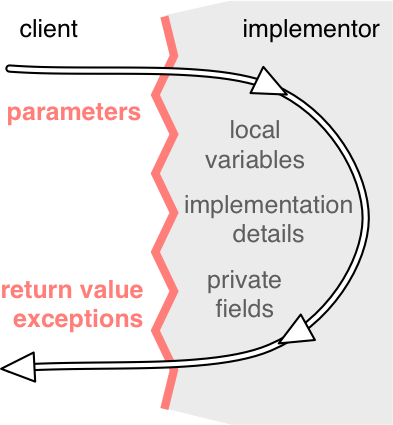
在 Java 中,方法的源代码通常无法提供给规格说明的读者,因为 Javadoc 工具会从您的代码中提取规格说明注释并将其呈现为 HTML。
测试和规格说明
在测试这一块,我们讨论那些根据规格说明选择的 黑盒测试,以及根据实际实现选择的 白盒测试(具体见 阅读材料 3:测试)。 但重要的是要注意,即使是白盒测试也必须遵循规格说明。您的实现可能提供比规格说明要求更强的保证,或者它可能具有规格说明未定义的特定行为。但您的测试用例不应依赖于该行为。测试用例必须遵守合同,就像每个其他使用者一样。
例如,假设您正在测试下面这个,和之前我们用的那个略有不同的 find 的规格说明:
static int find(int[] arr, int val)
requires: val occurs in arr
effects: returns index i such that arr[i] = val这个规格说明在某种意义上有一个强前置条件:val 必须能被找到;而在某种意义上它有一个相当弱的后置条件,即如果数组中 val 出现超过一次,这个规格说明对应该返回哪个 val 的索引没有任何说明。即使您实现的 find 总是返回最低索引,您的测试用例也不能假定特定的行为:
int[] array = new int[] { 7, 7, 7 };
assertEquals(0, find(array, 7)); // bad test case: violates the spec
assertEquals(7, array[find(array, 7)]); // correct类似地,即使您实现的 find 在未找到 val 时抛出异常,而不是返回一些任意的误导性索引,您的测试用例也不能假设该行为,因为它不能以违反前置条件的方式调用 find()。
那么,如果白盒测试不能超出规格说明,那它意味着什么?意味着您正在尝试在一种不受具体实现限制的情况下,找到新的测试样例用以锻炼实现的各个部分。
测试单元
回想一下 《阅读材料 3:测试》中网络搜索的例子 :
/** @return the contents of the web page downloaded from url */
public static String getWebPage(URL url) { ... }
/** @return the words in string s, in the order they appear,
* where a word is a contiguous sequence of
* non-whitespace and non-punctuation characters */
public static List<String> extractWords(String s) { ... }
/** @return an index mapping a word to the set of URLs
* containing that word, for all webpages in the input set */
public static Map<String, Set<URL>> makeIndex(Set<URL> urls) {
...
calls getWebPage and extractWords
...
}我们当时谈到了 单元测试 的概念,即我们应该独立地为程序的每个模块编写测试代码。一个好的单元测试专注于一个单一的规格说明。我们的测试几乎总是依赖于 Java 库方法的规格说明,但是我们编写的一个方法的单元测试不应该在 别的 方法未能满足其规格说明时失败。正如我们在示例中看到的,一个 extractWords 的测试不应该在 getWebPage 不满足其后置条件时失败。
良好的 集成测试,即使用多个模块的测试,将确保我们的不同方法具有兼容的规格说明:调用者和实现者如对方期望的那样传递和返回值。集成测试不能替代系统性地设计过的单元测试。举个例子,如果我们只通过调用 makeIndex 来测试 extractWords,我们只会在其输入空间的一个可能很小的部分上进行测试:这些输入是 getWebPage 的可能输出。这样做,我们留下了一个隐藏 bug 的地方,当我们在程序的其他地方使用 extractWords 用于不同目的时,或者当 getWebPage 开始返回以新格式编写的网页时,bug 就会跳出来。
可变方法的规格说明
我们之前讨论过可变对象和不可变对象,但我们的 find 规格说明例子并没有给我们机会在后置条件中描述副作用(对可变数据的修改)。
下面的规格说明描述了一个会改变对象的方法:
static boolean addAll(List<T> list1, List<T> list2)
requires: list1 != list2
effects: modifies list1 by adding the elements of list2 to the end of
it, and returns true if list1 changed as a result of call这份规格说明是从 Java List 接口的规格说明轻度简化而来的。首先,看看后置条件。它给出了两个约束:第一个告诉我们 list1 如何被修改,第二个告诉我们返回值是如何确定的。
其次,看看前置条件。它告诉我们,将列表元素添加到它本身这样的行为是未定义的。您可以很容易地想到为什么方法的实现者希望施加这种约束:想不到这样的行为有什么应用,并且这样可以让实现更为容易。规格说明允许一个简单的实现,在这个实现中,您从 list2 中取出一个元素并将其添加到 list1,然后继续到 list2 的下一个元素,直到到达末尾。如果 list1 和 list2 是同一列表,则此算法将不会终止 —— 这属于规格说明允许的范畴,因为它的前提条件。
还要记住我们的隐含前提条件,即 list1 和 list2 必须是有效对象,而不是 null。我们通常会省略这一点,因为几乎总是要求对象引用是有效的。
下面是另一个会改变状态的方法的例子:
static void sort(List<String> lst)
requires: nothing
effects: puts lst in sorted order, i.e. lst[i] <= lst[j]
for all 0 <= i < j < lst.size()一个不改变输入参数的例子:
static List<String> toLowerCase(List<String> lst)
requires: nothing
effects: returns a new list t where t[i] = lst[i].toLowerCase()正如我们所说的,除非另有说明,否则隐式禁止 null。我们也将使用下面的约定:除非另有说明,否则不允许使用可变对象。toLowerCase 的规格说明显式地说明了一个 作用(effect,后置条件) 是“lst 并为被修改”,但在一个缺失描述可变性的后置条件的情况下,我们要求不改变输入。
异常
既然我们正编写规格说明,并考虑用户将如何使用我们编写的方法,那么也让我们来讨论一下,如何以一种既避免出现错误又易于理解的方式来处理 异常(Exceptional Cases) 情况。
一个方法的 签名(Signature) —— 包括其名称、参数类型、返回类型 —— 是其规格说明的核心部分,而签名中还可能包含该方法可能触发的 异常(Exception)。
用于发出信号的异常
你可能已经在你的 Java 编程中遇到一些异常,例如 ArrayIndexOutOfBoundsException(当数组索引 foo[i] 超出数组 foo 的有效范围时抛出)或 NullPointerException(在尝试调用 null 对象引用的方法时抛出)。这些异常通常表示你的代码中存在错误,而 Java 在抛出异常时显示的信息可以帮助你找到并修复这些错误。
ArrayIndexOutOfBoundsException 和 NullPointerException 可能是此类异常中最常见的两个例子。其他例子包括:
ArithmeticException,抛出算术错误,例如整数除以零。NumberFormatException,由像Integer.parseInt这样的方法在传入无法解析为整数的字符串时抛出。
用于特殊结果的异常
异常不仅仅用于发出错误信号,它们还可以用来改善涉及特殊结果的程序结构。
一种不佳但常见的处理特殊结果的方法是返回特殊值。在 Java 库中的查找操作通常就是这样设计的:当期望得到一个正整数时,返回索引 -1;当期望得到一个对象引用时,返回 null。这种方法如果少用的话还可以,但它有两个问题。第一,检查返回值很繁琐。第二,很容易忘记检查它。(我们将看到,通过使用异常,你可以得到编译器的帮助。)
此外,并不总是容易找到一个“特殊值”。假设我们有一个 BirthdayBook 类,其中有一个查找方法。以下是一个可能的方法签名:
class BirthdayBook {
LocalDate lookup(String name) { ... }
}(LocalDate 是 Java API 的一部分。)
如果生日簿中没有给定姓名的条目,方法应该做什么?嗯,我们可以返回一些不会被用作真实日期的特殊日期。糟糕的程序员已经这样做了几十年;比如,他们会返回 9/9/99,因为很 明显,1960 年编写的程序在世纪末还在运行是不可想象的。(顺便说一句,他们错了。)
这里有一个更好的方法。该方法抛出一个异常:
LocalDate lookup(String name) throws NotFoundException {
// ...
if ( /* ...not found... */ )
throw new NotFoundException();
// ...
}然后调用者可以用 catch 子句处理这个异常。例如:
BirthdayBook birthdays = ...
try {
LocalDate birthdate = birthdays.lookup("Alyssa");
// we know Alyssa's birthday
} catch (NotFoundException nfe) {
// her birthday was not in the birthday book
}现在不再需要任何特殊值,也不需要与之相关的检查。
阅读:Java 教程中的 Exceptions (异常)。
受检查和无检查异常
我们已经看到异常的两个不同用途:特殊结果和错误检测。一般来说,你会希望使用受检查异常来表示特殊结果,使用无检查异常来表示程序错误。在后续部分,我们会对这一点进行一些细化。
一些术语:受检查异常 之所以被如此命名,是因为它们会被编译器检查:
- 如果一个方法抛出受检查异常,那么必须在其签名中声明这种可能性。
NotFoundException将是一个受检查异常,这也是签名以throws NotFoundException结尾的原因。 - 如果一个方法调用了另一个可能抛出受检查异常的方法,那么它必须要么处理该异常,要么在签名中声明该异常,因为如果没有在本地捕获,它将会向上传递给调用者。
因此,如果您在调用 BirthdayBook 的 lookup 方法时忘记处理 NotFoundException,编译器会报错。这非常有用,因为它确保了预期会发生的异常会被处理。
与之相反,无检查异常 用于发出程序出错的信号。这些异常通常不需要被代码捕获,除非在代码顶层您可能希望这样做。我们不希望调用链上的每个方法都必须声明它(可能)会抛出各种与错误相关的异常,比如索引越界、空指针、非法参数、断言失败等。
因此,对于无检查异常,编译器不会检查 try-catch 或 throws 声明。Java 仍然允许您在方法签名中为无检查异常添加 throws 子句,但这没有任何效果,因此这有点奇怪,我们也不建议这样做。
所有的异常都可以附带一条消息。如果它没有提供在构造函数中,那么对消息字符串的引用将为 null。
Throwable 的层级结构
为了理解 Java 如何决定异常是受检查异常还是无检查异常,让我们来看看 Java 的异常类的层级结构。
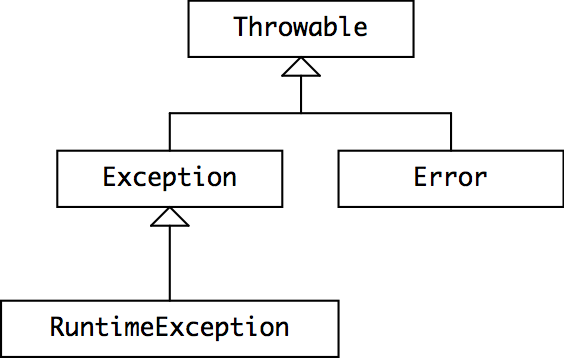
Throwable 是表示可抛出或捕获的对象的类。它的实现会在异常被抛出的位置记录堆栈跟踪信息,以及一个可选的描述异常的字符串。任何在 throw 或 catch 语句中使用的对象,或是在方法的 throws 子句中声明的对象,都必须是 Throwable 的子类。
Error 是 Throwable 的子类,它被保留,用作表示 Java 运行时系统产生的错误,例如 StackOverflowError 和 OutOfMemoryError。出于某种原因,AssertionError 也继承自 Error,尽管它表示用户代码中存在 Bug,而非运行时中。Error 应被视为是不可恢复的(unrecoverable),并且通常不会被捕获。
下面是 Java 区分受检查异常和无检查异常的方法:
RuntimeException、Error以及它们的子类是 无检查 异常。编译器不会要求它们在一个抛出它们的方法的throws子句中被声明,并且不要求它们被调用者(例如一个方法)捕获或声明。- 所有其他可抛出的对象 ——
Throwable、Exception、以及它们的除了RuntimeException和Error一脉的子类 —— 都是 受检查 异常。编译器要求在可能引发这些异常时捕获或声明这些异常。
在您定义自己的异常时,您应该使其要么继承自 RuntimeException (使其成为一个无检查异常),要么继承自 Exception(使其受检查)。程序员通常不会继承 Error 或 Throwable,因为它们被 Java 自身保留。
异常设计的注意事项
我们给出的规则 —— 对特殊情况(即预期情况)使用受检查异常,对 Bug(未预料的报错)使用无检查异常 —— 是有道理的,但这并不是关于异常的全部内容。问题在于,Java 中的异常并不那么轻量。
除了性能损失外,Java 中的异常还会产生另一个(更严重的)成本:它们很难用,无论是在方法的设计还是在方法的使用中。如果您 设计 一个包含它自己的(新的)异常的方法,你必须为这个异常创建一个新的类。如果您 调用 一个会抛出受检查异常的方法,您必须将其包裹在 try-catch 语句块中(即使您知道这个异常永远不会被抛出)。后一项规定使您陷入一个两难境地。例如,假设您正在设计一个抽象队列。当队列为空时,这个队列应该抛出一个受检查异常吗?假设您希望在客户端支持一种编程风格,即在循环中不断弹出队列直到异常被抛出。因此您选择使用受检查异常。现在,某个客户端希望在调用该方法时,在弹出队列之前先检测队列是否为空,仅在队列不为空时才进行弹出操作。令人沮丧的是,该客户端仍需将调用包裹在 try-catch 语句中。
这引出了一个更精细的规则:
- 您应仅在需要指示意外故障(即 Bug)时使用无检查异常,或在预期客户端通常会编写确保异常不会发生的代码时使用,因为存在一种方便且成本低廉的方法来避免该异常;
- 否则您应该使用受检查异常。
以下是一些将此规则应用于假设方法的示例:
- 当队列为空时,
Queue.pop()会抛出一个 无检查 的EmptyQueueException,因为可以合理地期望调用方通过调用Queue.size()或Queue.isEmpty()等方法来避免这种情况。 Url.getWebPage()在无法获取网页时抛出 受检查 的IOException,因为调用方难以预防此类情况。int integerSquareRoot(int x)在x没有整数平方根时抛出一个 受检查 的NotPerfectSquareException,因为测试x是否为完全平方数与实际找到平方根一样困难,因此不合理地期望调用方来防止这种情况。
在 Java 中使用异常的成本是许多 Java API 使用空引用作为特殊值的原因之一。只要谨慎使用并仔细指定,这并不是一件糟糕的事情。
异常的滥用
下面是一个来自 Joshua Bloch 的 Effective Java 中的例子(第二版,第 57 条)。
try {
int i = 0;
while (true)
a[i++].f();
} catch (ArrayIndexOutOfBoundsException e) { }这段代码的作用是什么?仅从代码表面观察,其功能并不明显,而这正是我们不应使用它的充分理由。... 当代码尝试访问数组范围之外的第一个数组元素时,无限循环会通过抛出、捕获并忽略一个
ArrayIndexOutOfBoundsException异常来终止。
它应该等价于:
for (int i = 0; i < a.length; i++) {
a[i].f();
}或者(使用合适的类型 T):
for (T x : a) {
x.f();
}Bloch 写道,基于异常的编程模式:
... 是一种基于错误推理的错误尝试,试图通过以下逻辑来提升性能:由于虚拟机(VM)会检查数组访问的边界,因此正常的循环终止条件(
i < a.length)是多余的,应予以避免。
然而,由于 Java 中的异常设计仅用于特殊情况,因此几乎没有 JVM 实现会尝试优化其性能。在典型机器上,当从 0 循环到 99 时,基于异常的编程模式比标准模式慢 70 倍。
更糟糕的是,基于异常的编程模式甚至无法保证正常工作!假设在循环体中对 f() 的计算存在一个错误,导致对某个无关数组的越界访问。会发生什么情况?
如果使用了合理的循环语法,该漏洞会引发一个未捕获的异常,导致线程立即终止并生成完整的堆栈跟踪。如果使用了错误的基于异常的循环,与漏洞相关的异常会被捕获并误认为是正常的循环终止。
总结
在结束之前,让我们通过一个最后的例子来检验你的理解:
规格说明在程序实现者与程序使用者之间起到关键的防火墙作用。它使独立开发成为可能:使用者可以自由编写使用该程序的代码而无需查看其源代码,而实现者也可以自由编写实现该程序的代码而无需了解其具体使用方式。
让我们回顾一下规格说明说明如何帮助实现本课程的主要目标:
- 远离 Bugs。良好的规格说明明确记录了使用者与实现者之间依赖的共同假设。bug 通常源于接口处的分歧,而规格说明的存在可减少此类问题。在规格说明中使用机器可验证的语言特性(如静态类型和异常,而非仅靠人类可读的注释)可进一步降低 bug 风险。
- 易于理解。简短、简单的规格说明比实现本身更易于理解,并能让其他人无需阅读代码。
- 为变更做好准备。规格说明在代码的不同部分之间建立契约,只要这些部分继续满足契约的要求,它们就可以独立变更。